Context Engineering¶
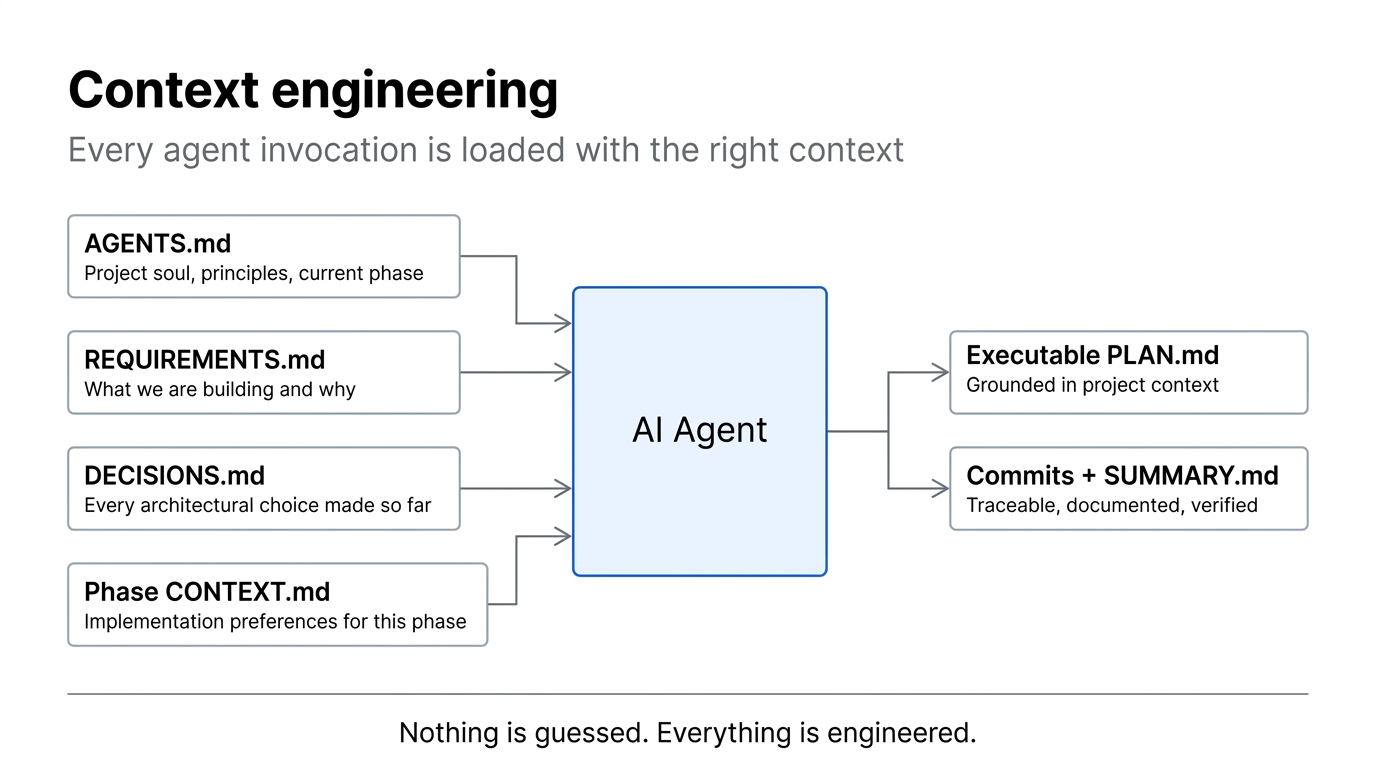
The difference between a good AI agent output and a mediocre one is almost always context quality. learnship doesn't let agents guess: every invocation is loaded with the right structured context for what it needs to do.
The problem with raw AI agents¶
Without structured context, every AI session starts cold:
- The agent doesn't know your tech stack
- It doesn't know what decisions you've already made
- It doesn't know which phase you're in or what was built before
- It makes assumptions: and those assumptions become bugs
The naive fix (pasting context manually at the start of every session) is fragile, inconsistent, and exhausting.
How learnship solves it¶
flowchart LR
subgraph CONTEXT["Loaded into every agent call"]
A["AGENTS.md<br/>Project soul + current phase"]
B["REQUIREMENTS.md<br/>What we're building"]
C["DECISIONS.md<br/>Every architectural choice"]
D["Phase CONTEXT.md<br/>Implementation preferences"]
end
CONTEXT --> AGENT["AI Agent"]
AGENT --> P["Executable PLAN.md"]
AGENT --> S["Commits + SUMMARY.md"]AGENTS.md: persistent project memory¶
Generated by /new-project and placed at your project root. Your AI platform reads it as a system rule at the start of every conversation: automatically, without any action from you.
AGENTS.md
├── Soul & Principles # Pair-programmer framing, 10 working principles
├── Platform Context # Points to .planning/, explains the phase loop
├── Current Phase # Updated automatically by workflows
├── Project Structure # Filled from your new-project answers
├── Tech Stack # Filled from domain research
└── Regressions # Updated by /debug when bugs are fixed
Every workflow updates AGENTS.md when the phase advances: so the agent always knows where the project stands.
DECISIONS.md: the decision register¶
## DEC-001: Use Zustand over Redux
Date: 2026-03-01 | Phase: 2 | Type: library
Context: Needed client-side state for dashboard filters
Options: Zustand (simple), Redux (complex, overkill for scope)
Choice: Zustand
Rationale: 3x less boilerplate, sufficient for current data flow
Consequences: Locks React as UI framework
Status: active
The planner reads DECISIONS.md before creating any plans and never contradicts active decisions. The debugger adds lessons from bugs. /audit-milestone checks that decisions were honored.
Phase CONTEXT.md: your preferences per phase¶
Before planning, /discuss-phase writes your implementation preferences to .planning/phases/N-*/N-CONTEXT.md. The planner reads this and creates plans that match your choices: not generic best practices.
Parallel execution with full context budgets¶
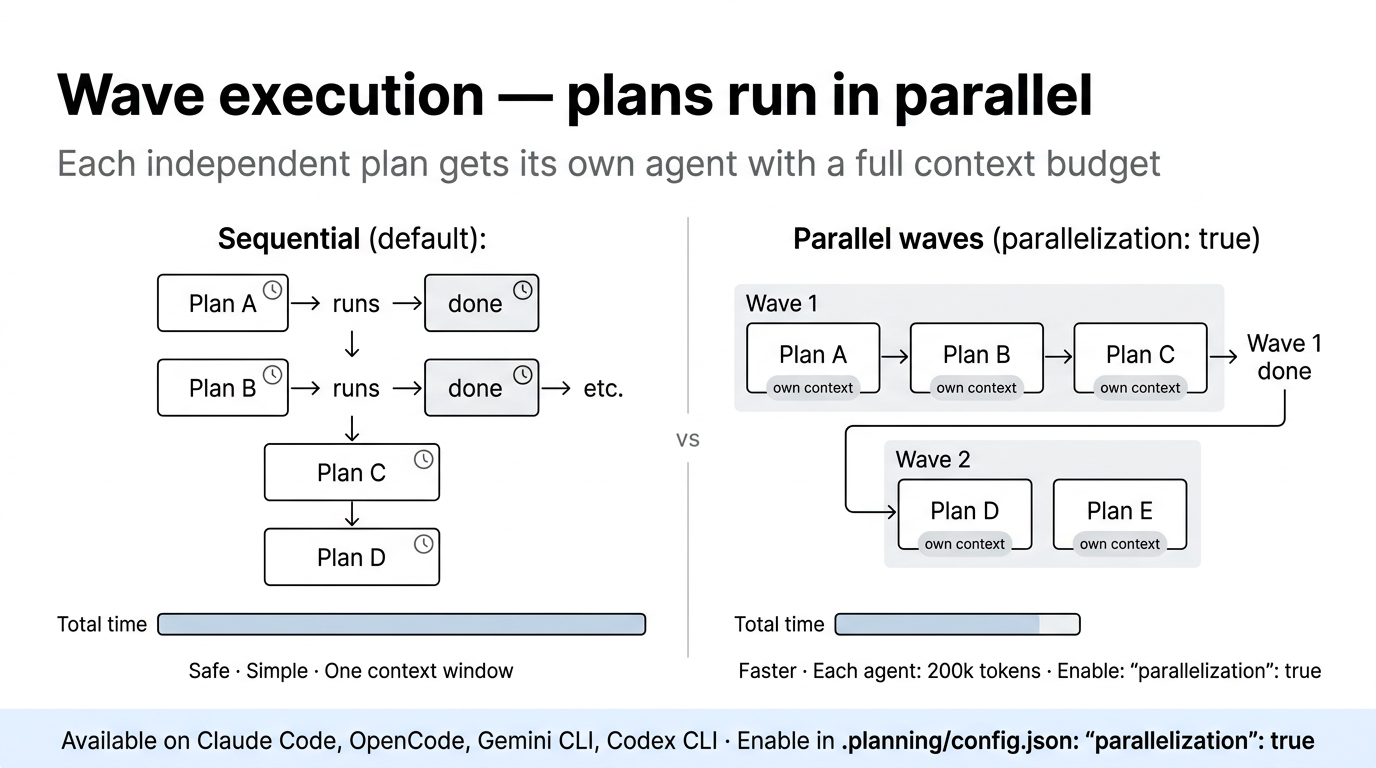
On Claude Code, OpenCode, and Codex CLI, parallel subagents are on by default: execute-phase dispatches each independent plan to its own dedicated executor agent with a full 200k token context budget. Plans in the same wave run in parallel.
| Mode | Context per agent | Speed |
|---|---|---|
| Parallel (default on Claude Code, OpenCode, Codex) | 200k each | Faster, more thorough |
| Sequential | Shared | Predictable, one plan at a time |
To disable parallel execution: set "parallelization": { "enabled": false } in .planning/config.json.
Windsurf, Cursor, and Gemini CLI
These platforms use sequential execution. Windsurf and Cursor have no Task() subagent API available to learnship workflows. Gemini CLI's parallel execution is experimental and disabled by default.
What "nothing is guessed" means in practice¶
| Without context engineering | With learnship |
|---|---|
| Agent picks a random auth library | Agent uses the one you chose in CONTEXT.md |
| Agent forgets decisions made 3 sessions ago | Agent reads DECISIONS.md: every decision is live |
| Agent creates plans that conflict with your architecture | Planner reads AGENTS.md and the decision register |
| Plans break in later phases | Planner sees REQUIREMENTS.md and REQ-IDs |